Abgeschlossene Projekte
InnoHub 13 - fast track to transfer TP 05 - Entwicklung und Betrieb der digitalen Plattform des Innovation Hubs 13
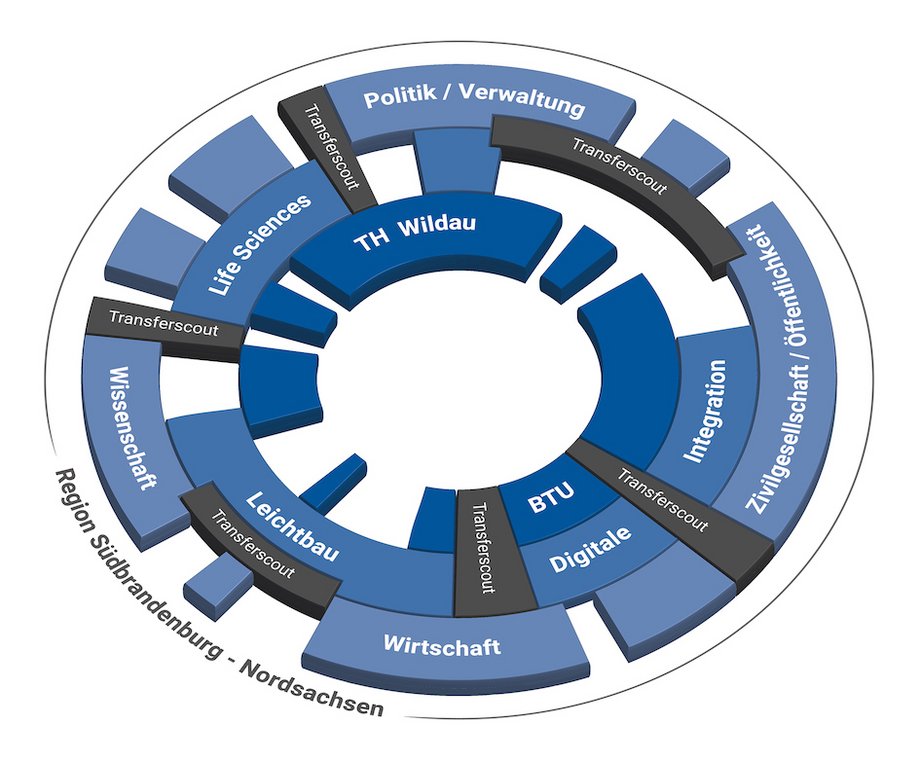
Der „Innovation Hub 13” ist ein Projekt der Technischen Hochschule Wildau und der Brandenburgischen Technischen Universität Cottbus-Senftenberg zur Förderung des Wissens- und Technologietransfers zwischen Hochschulen, Unternehmen und Öffentlichkeit. Er verfolgt seit dem Projektstart 2018 das Ziel, die Region entlang der A13 zu stärken. Beide Hochschulen bekennen sich damit neben Forschung und Lehre aktiv zur „Third Mission“.
Ansprechpartner:Prof. Ingo Schmitt
Verfahren der Industrie 4.0 für die Triebwerks-Vorauslegung (VIT-V)
- Projektträger: Das Land Brandenburg und die EU
- Forschungspartner: Rolls-Royce Deutschland Ltd & Co KG
- Laufzeit: 36 Monate (07/2018 - 06/2021)
- Teilprojekt: Datenmanagement und -analyse in der Triebwerkstechnik
- Hauptaufgabe: Analyse des Zusammenhangs von Geometrievariationen von Schaufelblättern und deren Verhalten im Rahmen von aero-mechanischen Analysen
- Bereiche: Datenbanksysteme, Data Warehouse, Data Mining, Machine Learning
- Teil-Projektleitung: Prof. Schmitt, I.
Ansprechpartner:Prof. Ingo Schmitt, Rrezart Murtezaj M.Sc.
Quantum Information Access and Retrieval Theory (QUARTZ)
- Projektmaßnahme: Horizon 2020, European Training Networks (MSCA-ITN-ETN)
- Projektträger: European Commission, Research Executive Agency
- Partner: University Padova (Italy), Open University (Uk), University of Bedfordshire (UK) Vrije Universiteit (Belgium), Kobenhavns Universitet (Denmark), Linneuniversitetet (Sweden)
- Laufzeit: 36 months
- Teilprojekt: Supervision and training in quantum mechanics and -logic.
- Teil-Projektleitung: Prof. Schmitt, I.
Ansprechpartner:Prof. Ingo Schmitt, Yousef Younes M. Sc.
Cottbus.de

Cottbus.de ist das Content-Management-System für den Internetauftritt der Stadt Cottbus, welches am Lehrstuhl für die Stadt Cottbus entwickelt wurde. Eingesetzte Werkzeuge hierbei sind PosgreSQL, Perl, XML und XSLT.
Im Rahmen dieses Projektes gibt es eine enge Kooperation zwischen dem Lehrstuhl Datenbank- und Informationsysteme (DBIS), der Stadtverwaltung Cottbus und der Cornell Binder, Sven Schoradt GbR.
Der Lehrstuhl DBIS ist dabei insbesondere für die konzeptionelle Weiterentwicklung und Umsetzung neuer Anwendungsfälle verantwortlich. Dies geschieht i.d.R. mit Hilfe von studentischen Abschlussarbeiten. Die Stadtverwaltung Cottbus fungiert als Auftrag- und Ideengeber, sowie als Ersteller und Nutzer der Inhalte. Die Cornell Binder, Sven Schoradt GbR, eine Firma zweiter ehemaliger Studenten des Lehrstuhl DBIS, setzt Ergebnisse in das laufende System um, ist zuständig für Wartung und Weiterenticklung des Systems.
Projektbeteiligte
Ansprechpartner:Prof. Ingo Schmitt
OpenInfRA - Ein webbasiertes Informationssystem zur Dokumentation und Publikation archäologischer Forschungsprojekte

DFG-Projekt 2011 - 2015
Zusammenfassung:
Bei altertumswissenschaftlichen Feldforschungen unter Beteiligung unterschiedlicher Disziplinen werden heute Daten zumeist in digitaler Form gesammelt. Da diese häufig nicht nachhaltig gesichert, veröffentlicht und vernetzt sind, soll ein webbasiertes Informationssystem entwickelt und für die archäologischen Fächer und die Bauforschung frei zur Verfügung gestellt werden, sowohl für Projekte an Universitäten, Museen, Akademien, dem DAI und anderen Institutionen als auch für ausländische Kooperationspartner.
OpenInfRA soll ein breites Spektrum von Arbeitsmethoden und Themen berücksichtigen, individuell zu modifizieren und auf strukturelle Einheitlichkeit ausgerichtet sein, um eine projektübergreifende Auswertung von Daten zu vereinfachen. Durch die Bereitstellung umfangreicher Recherchefunktionen sowie die Einbindung externer Ressourcen und Applikationen wird ein hohes Maß an Interoperabilität angestrebt. Neue Funktionen zur Verarbeitung, Analyse und Präsentation von 3D-Geometrien werden entwickelt, um räumliche Zusammenhänge durch die Integration webbasierter GIS-Funktionalitäten besser darstellen zu können. Die Möglichkeit zur zeitnahen, digitalen Publikation umfassender Datenbestände und deren Kommentierung durch Nutzer soll die zeit- und ortsunabhängige Zusammenarbeit von Wissenschaftlern sowie neue Formen des Diskurses in der Altersforschung fördern.
OpenInfRA wird im Rahmen der Ausschreibung „Informationsinfrastrukturen für Forschungsdaten“ seit Juni 2011 von der Deutschen Forschungsgemeinschaft gefördert.
Projektbeteiligte
- Lehrstuhl für Vermessungskunde der BTU Cottbus (Prof. Dr.-Ing Klaus Rheidt)
- Fakultät Geoinformation der HTW Dresden (Prof. Dr.-Ing. Frank Schwarzbach)
- Deutsches Archäologisches Institut, Berlin
Ansprechpartner:Alexander Schulze
Multimediale Ähnlichkeitssuche zum Matchen, Typologisieren und Segmentieren (Phase II)

BMBF-Projekt für 10 Mitarbeiter : 01.10.2010-30.09.2012
In der 3. Ausschreibungsrunde des BMBF-ForMaT-Programms war der Lehrstuhl Datenbank- und Informationssysteme in Zusammenarbeit mit dem Lehrstuhl für Marketing und Innovationsmanagement (Prof. Daniel Baier) unter den 9 ausgewählten Projekten, die mit einer Fördersumme von jeweils bis zu 1,5 Mio. Euro bedacht werden.
Zusammenfassung:
Die Aufgabe einer Ähnlichkeitssuche ist es, in einer evtl. sehr großen Menge von Objekten diejenigen Objekte (z.B. Personen, Tiere, Pflanzen, Musikstücke, Filme usw.) zu finden, die ein vorgegebenes Suchkriterium am besten erfüllen. Bekannt ist die Suche nach geeigneten Webseiten oder Bildern im World Wide Web, bei der einer Suchmaschine (z.B. www.google.de oder images.google.de) Stichwörter vorgegeben werden.
Bei einer multimedialen Ähnlichkeitssuche geht es nun darum, die Ähnlichkeitssuche und –bewertung von Objekten dahingehend zu erweitern, dass zusätzlich oder alternativ auch andere verfügbare Informationen (z.B. die Bilder/Videos von Personen, Tieren, oder Ausschnitte aus Musikstücken, Filmen) genutzt werden.
Das mit diesem Konzept vorgeschlagene Innovationslabor soll die an der BTU Cottbus in DFG-Projekten und Dissertationen erzielten, international vorgestellten und publizierten Forschungsergebnisse zu diesem Thema in einer kommerziellen Verwertung zugänglich machen. Wesentliche, in Phase 2 des Projekts zu erarbeitende Elemente dieser Verwertungsstrategie sind:
- eine flexibel nutzbare Software zur Ähnlichkeitssuche in Multimediadaten,
- eine (Software-)Bibliothek zur statistischen Analyse sowie
- verschiedene Dienstleistungsangebote ("Customizing und Algorithmenforschung“).
Ansprechpartner:David Zellhöfer
SQ-System: Entwicklung von Konzepten für ein quantenlogikbasiertes Retrieval-Datenbank-Anfragesystem: Anfragesprache, interaktive Suchformulierung sowie effiziente Anfrageauswertung
DFG-Projekt für 2 Mitarbeiter 2010-2013
Zusammenfassung:
Die Suche in einem klassischen Datenbanksystem basiert auf Prädikatenlogik erster Ordnung. Dort können die Daten eine Anfrage nur erfüllen oder nicht erfüllen. Diese so genannten Datenbankbedingungen unterstützen keine graduelle Erfüllung. Dies ermöglichen jedoch Retrieval-Systeme mit Retrieval-Bedingungen, welche auf völlig anderen Konzepten, zum Beispiel dem Vektorraummodell, basieren. Damit stellen Retrieval-Bedingungen gegenüber den konventionellen Datenbankbedingungen ein weiteres Suchparadigma dar. Viele moderne Anwendungen, zum Beispiel aus dem Bereich Multimedia, Web und XML, benötigen jedoch die Kombination von Datenbank- und Retrieval-Bedingungen. Die Problematik der Integration dieser Paradigmen für ein "Reasoning about Uncertain Data" wurde von führenden Datenbankforschern im aktuellen Lowell-Report als wichtiges Forschungsziel identifiziert. Kernidee des Projektes ist die Integration durch Konzepte eines Retrieval-Datenbank-Anfragesystems auf der Grundlage des vereinheitlichenden Formalismus der Quantenmechanik und Quantenlogik. Dieser Ansatz erlaubt die Einbettung von Datenbank- und Retrieval-Konzepten und schlägt eine elegante Brücke zwischen linearer Algebra, Logik und Wahrscheinlichkeitsrechnung. Damit werden Ergebnisse aus diesen gut erforschten Gebieten zur Lösung von Datenbank- und Retrieval-Fragestellungen erschlossen.
Ansprechpartner: Sebastian Lehrack
Demo-Webseite: ProQua
Generic Indexing
In diesem Projekt wird für die effiziente Nächste-Nachbar-Suche an Hand einer Metrik ein Metrikindex entwickelt. Eine solche Suche ermöglicht die schnelle Ähnlichkeitssuche in großen Kollektionen von Multimediadaten. Eine Bildsuche auf ca. 100000 Bildern demonstriert dies anschaulich.
Ansprechpartner:Marcel Zierenberg