Unified Approach to Signal Synthesis and Recognition (UASR, 2000–today)
Abstract
UASR (unified approach to signal synthesis and recognition) is a long-term framework project on hierarchical cognitive signal processing systems, including speech dialog systems. Fig. 1 shows the basic system flow-chart.
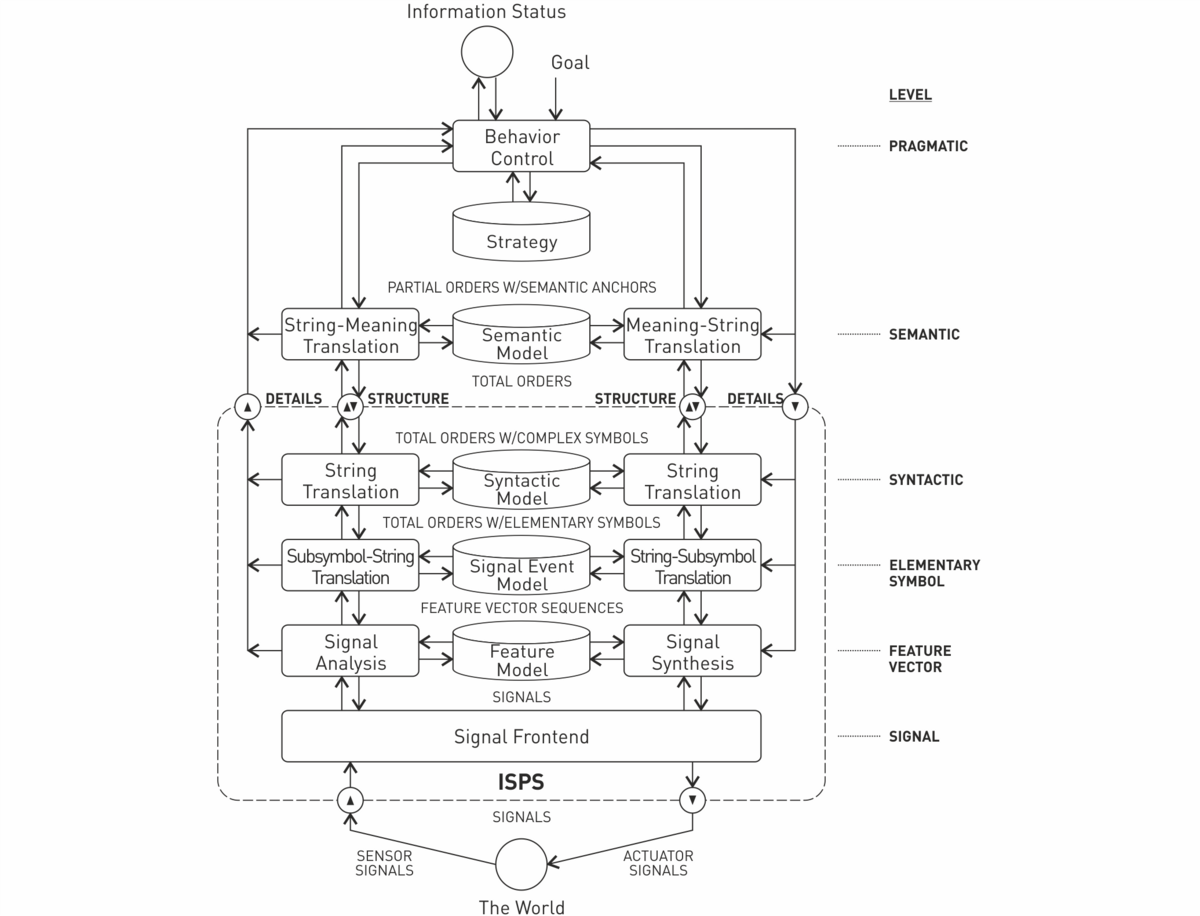
Fig. 1: UASR basic flow chart (ISPS = intelligent signal processing system).
UASR was originally started by the chair of systems theory and speech technology at TU Dresden and is now being continued by the chair of communications engineering at BTU Cottbus–Senftenberg and other partners.
The project aims
- to unify mathematical description and algorithmic implementation of the perception and action signal processing paths by means of finite state machines and Petri net transducers [LHW14] and to translate seamlessly between signal and meaning and vice versa,
- to model perception and action strictly as inverse systems sharing the same memory which allows to model and study technical, biological and speech signals by a closed-loop multilevel analysis-by-synthesis approach, and
- to provide a new “algebra of meaning” using weighted labeled partial orders (wLPO) as semantic carriers and to construct a “think engine” basing on a wLPO algebra.
Applications of UASR include
- speech dialog systems (see Fig. 2 and e.g. [WL13, WHK+12, SW11, SWD+09, HWJ+08, PLW+07, HEW07, WEW+04, EWH00, Str14, Geb13, Hus13, Pet09, Wer08, Eic07, Wol04]),
- intelligent signal processing systems (e.g. [HW12, WH12]),
- acoustic pattern recognizers for various tasks (e.g. [TW09, WT09, WSH+08, Duc14, Wit12, Tsc12, Wol11]), and
- music and bio-signal processing applications (e.g. [TWS15, PWF12, EWH08, WKH+07, Pae14, Hue15]).
UASR is available as open source software (see UASR and dLabPro @GitHub) and, partly, in form of cyber-physical systems (see MiSIS and UCUI projects).
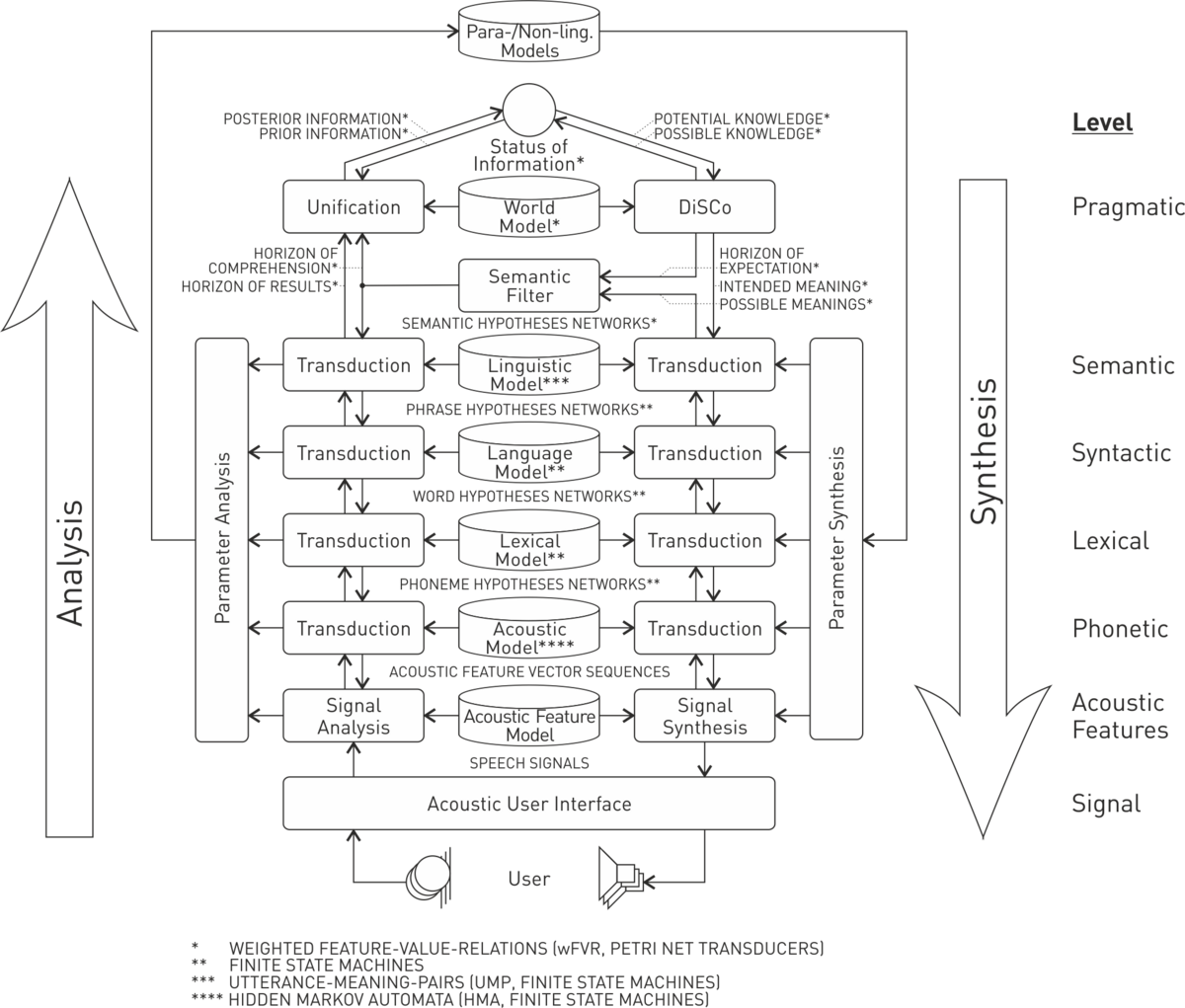
Fig. 2: Flow chart of UASR speech dialog system
Current research includes
- an embedded universal cognitive user interface and an intelligent signal processing system,
- formal and technical models of higher cognitive functions (e.g. sub-text analysis, coping and imagination [Kli13, WRW15]),
- semantic algebra and think engines (e.g. [RHW16, WL14, Wir12]),
- medical applications (e.g. [TWS15]).
Project Facts
| Partners |
|
| Funding |
|
| Contact | Prof. Dr.-Ing. habil. Matthias Wolff |
Selected Publications
[RHW16] R. Römer, M. Huber, G. Wirsching: Ein Beitrag zur Gedankengeometrie kognitiver Systeme. In proc. 27th Konferenz Elektronische Sprachsignalverarbeitung (ESSV2016), pp. 101-110, 2016.
[TWS15] C. Tschöpe, M. Wolff, G. Saeltzer: Estimating Blood Sugar from Voice Samples: A Preliminary Study. In proc. International Conference on Computational Science and Computational Intelligence (CSCI 2015), pp. 804-805, 2015. (full text)
[WRW15] M. Wolff, R. Römer and G. Wirsching: Towards coping and imagination for cognitive agents. In proc 6th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), pp. 307-312, 2015.
[WL14] G. Wirsching, R. Lorenz: Some Algebraic Aspects of Semantic Uncertainty and Cognitive Biases. In proc. 5th IEEE Int. Conf. on Cognitive Infocommunications, 2014.
[LHW14] R. Lorenz, M. Huber, G. Wirsching: On Weighted Petri Net Transducers. In proc. 35th International Conference on Application and Theory of Petri Nets and Concurrency, pp. 233-252, 2014.
[WL13] G. Wirsching, R. Lorenz: Towards Meaning-Oriented Language Modeling. In proc. IEEE 4th International Conference on Cognitive Infocommunications (CogInfoCom), pp. 369-374, 2013.
[HW12] R. Hoffmann, M. Wolff: Towards hierarchical cognitive systems for intelligent signal processing. In proc. ICT Innovations 2012, Secure and Intelligent Systems, pp. 613-618, 2012.
[PWF12] S. Päßler, M. Wolff, W.-J. Fischer: Food intake monitoring: An acoustical approach to automated food intake activity detection and classification of consumed food. Physiological Measurement 33(6):1073-1093, 2012.
[WH12] M. Wolff, R. Hoffmann: An Approach to Intelligent Signal Processing. In: A. Esposito et al. (Eds.): Cognitive Behavioral Systems. Berlin etc.: Springer 2012 (LNCS vol. 7403), pp. 1-18, 2012.
[Roe12] R. Römer: A Cortical Approach Based on Cascaded Bidirectional Hidden Markov Models. In: A. Esposito et al. (Eds.): Cognitive Behavioural Systems. Berlin etc.: Springer 2012 (LNCS vol. 7403), pp. 266-272, 2012.
[Wir12] G. Wirsching: Calculating semantic uncertainty. In proc. IEEE 3rd International Conference on Cognitive Infocommunications (CogInfoCom), pp. 71-76, 2012.
[WHK+12] G. Wirsching, M. Huber, C. Kölbl, R. Lorenz, R. Römer: Semantic Dialogue Modeling. In: A. Esposito et al. (Eds.): Cognitive Behavioral Systems. Berlin etc.: Springer 2012 (LNCS vol. 7403), pp. 104-113, 2012.
[DW11] F. Duckhorn, M. Wolff: A new Epsilon Filter für Efficient Composition of Weighted Finite-State Transducers. In proc. Annual Conference of the International Speech Communication Association (Interspeech 2011), 2011.
[SW11] G. Strecha, M. Wolff: Speech synthesis using HMM based diphone inventory encoding for low-resource devices. In proc. 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2011), 5380-5383, 2011.
[TW09] C. Tschöpe, M. Wolff: Statistical classifiers for structural health monitoring. Sensors Journal, IEEE, 9(11):1567-1576, October 2009.
[WT09] M. Wolff, C. Tschöpe: Pattern recognition for sensor signals. In proc. of the IEEE Sensors Conference 2009, pp. 665-668, 2009.
[SWD+09] G. Strecha, M. Wolff, F. Duckhorn, S. Wittenberg, C. Tschöpe: The HMM synthesis algorithm of an embedded unified speech recognizer and synthesizer. In proc. Proceedings of the Annual Conference of the International Speech Communication Association 2009 (INTERSPEECH 2009), pp. 1763-1766, 2009.
[EWH08] M. Eichner, M. Wolff, R. Hoffmann: An HMM Based Investigation of Differences Between Musical Instruments of the Same Type. In proc. 19th International Congress on Acoustics (ICA 2007), 2007.
[HWJ+08] H. Hussein, M. Wolff, O. Jokisch, F. Duckhorn, G. Strecha, R. Hoffmann: A hybrid speech signal based algorithm for pitch marking using finite state machines. In proc. 9th annual conference of the International Speech Communication Association 2008 (INTERSPEECH 2008), pp. 135-138, 2008.
[WSH+08] M. Wolff, R. Schubert, R. Hoffmann, C. Tschöpe, E. Schulze, H. Neunübel: Experiments in Acoustic Structural Health Monitoring of Airplane Parts. In proc. IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2008), pp. 2037-2040, 2008.
[PLW+07] R. Petrick, K. Lohde, M. Wolff, R. Hoffmann: The harming part of room acoustics in automatic speech recognition. In proc. Annual Conference of the International Speech Communication Association (INTERSPEECH 2007), pp. 1094-1097, 2007.
[WKH+07] M. Wolff, U. Kordon, H. Hussein, M. Eichner, C. Tschöpe, R. Hoffmann: Auscultatory blood pressure measurement using HMMs. In proc IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), pp. 405-408, 2007.
[HEW07] R. Hoffmann, M. Eichner, M. Wolff: Analysis of verbal and nonverbal acoustic signals with the Dresden UASR system. In: A. Esposito et al. (Eds.): Verbal and Nonverbal Communication Behaviours. Berlin etc.: Springer 2007 (LNAI vol. 4775), pp. 200-218.
[WEW+04] S. Werner, M. Eichner, M. Wolff, R. Hoffmann: Toward spontaneous speech synthesis - Utilizing language model information in TTS. IEEE Trans. on Speech and Audio Processing 12 (2004) 4, 436-445.
[EWH00] M. Eichner, M. Wolff, R. Hoffmann: A unified approach for speech synthesis and speech recognition using stochastic Markov graphs. Proc. ICSLP, Beijing 2000, vol. 1, 701-704.
Selected Doctoral and Habilitation Theses:
[Hue15] S. Hübler: Rhythmische Musikanalyse und -erkennung. Dissertationsschrift, TU Dresden. Dresden: TUDpress 2015 = Studientexte zur Sprachkommunikation, Bd. 76.
[Duc14] F. Duckhorn: Suchraumoptimierung mit gewichteten endlichen Automaten in der akustischen Mustererkennung. Dissertationsschrift, TU Dresden. Dresden: TUDpress 2014 = Studientexte zur Sprachkommunikation, Bd. 73.
[Str14] G. Strecha: Skalierbare akustische Synthese für konkatenative Sprachsynthesesysteme. Dissertationsschrift, TU Dresden. Dresden: TUDpress 2014 = Studientexte zur Sprachkommunikation, Bd. 77.
[Pae14] S. Päßler: Analyse des menschlichen Ernährungsverhaltens mit Hilfe von Kaugeräuschen. Dissertationsschrift, TU Dresden. Dresden: TUDpress 2014 = Studientexte zur Sprachkommunikation, Bd. 72.
[Kli13] P. Klimczak: Formale Subtextanalyse - Kalkülisierung von Narration und Interpretation. Dissertationsschrift, BTU Cottbus-Senftenberg, 2013. mentis Verlag GmbH, 2016.
[Geb13] Y. B. Gebremedhin: Speech Recognition-Synthesis System for Amharic. Dissertationsschrift, TU Dresden. Dresden: TUDpress 2013 = Studientexte zur Sprachkommunikation, Bd. 66.
[Hus13] H. Hussein: Prosodic Analysis and Synthesis – Application in Computer-Assisted Language Learning. Dissertationsschrift. Dresden: TUDpress 2013 = Studientexte zur Sprachkommunikation, Bd. 69.
[Wit12] S. Wittenberg: Statistische Ein-Klassen-Signalbewertung mit akustischen Datenbasen selbstbeschreibender Daten. Dissertationsschrift, TU Dresden. Dresden: TUDpress 2012 = Studientexte zur Sprachkommunikation, Bd. 63.
[Tsc12] C. Tschöpe: Akustische zerstörungsfreie Prüfung mit Hidden-Markov-Modellen. Dissertationsschrift, TU Dresden. Dresden: TUDpress 2012 = Studientexte zur Sprachkommunikation, Bd. 60.
[Wol11] M. Wolff: Akustische Mustererkennung. Habilitationsschrift, TU Dresden. Dresden: TUDpress 2011 = Studientexte zur Sprachkommunikation, Bd. 57.
[Pet09] R. Petrick: Robuste Spracherkennung unter raumakustischen Umgebungsbedingungen. Dissertationsschrift, TU Dresden. Dresden: TUDpress 2012 = Studientexte zur Sprachkommunikation, Bd. 49.
[Wer08] S. Werner: Sprachsynthese und Spracherkennung mit gemeinsamen Datenbasen - Sprachmodell und Aussprachemodellierung. Dissertationsschrift, TU Dresden. Dresden: TUDpress 2008 = Studientexte zur Sprachkommunikation, Bd. 48.
[Eic07] M. Eichner: Sprachsynthese und Spracherkennung mit gemeinsamen Datenbasen - Akustische Analyse und Modellierung. Dissertationsschrift, TU Dresden. Dresden: TUDpress 2007 = Studientexte zur Sprachkommunikation, Bd. 43.
[Wol04] M. Wolff: Automatisches Lernen von Aussprachewörterbüchern. Dissertationsschrift, TU Dresden. Dresden: w.e.b. Universitätsverlag 2004 = Studientexte zur Sprachkommunikation, Bd. 32.
Reports
[WT07] M. Wolff, C. Tschöpe: Entwicklung von Datenanalyseverfahren für die Qualitätsbewertung technischer Prozesse, basierend auf spektralen Repräsentationen akustischer Vorgänge, Abschlussbericht zum DFG-Projekt HE 3656/1-1 und HO 1674/8-1, 15.12.2007, 43 Seiten.
[CEW+02] M. Cuevas, M. Eichner, S. Werner, M. Wolff: Integration von Spracherkennung und -synthese unter Verwendung gemeinsamer Datenbasen. Abschlussbericht zum DFG-Projekt HO 1674/7
[EWW+02] M. Eichner, S. Werner, M. Wolff, R. Hoffmann: Integration von Spracherkennung und -synthese unter Verwendung gemeinsamer Datenbasen. DFG Zwischenbericht und Fortsetzungsantrag, Institute of Acoustics and Speech Communication, Dresden University of Technology, 2002. Ho 1674/7-1.
[WEH00] M. Wolff, M. Eichner, R. Hoffmann: Entwicklung von Lösungen zum strukturellen Training hierarchisch organisierter Aussprachewörterbücher. DFG Abschlußbericht, Institute of Acoustics and Speech Communication, Dresden University of Technology, December 2000. Ho 1674/3.